Ejemplo de extracción de RDFa de una página
El conjunto de extensiones RDFa nos permite introducir semántica en un contenido web. De forma que la información sea entendible por seres humanos y a la vez incorpore semántica que pueda procesar una máquina. GRDDL es un método para extraer de una página web con contenido RDFa el archivo RDF asociado. Es decir, un fichero RDF con la información semántica de la página.
En este capítulo vamos a ver de forma práctica cómo se aplica GRDDL a una URL para obtener el archivo RDF asociado. Para ello, existen varias implementaciones en distintos lenguajes. Veremos dos métodos, uno con un servicio online y otro con un cliente escrito en Python.
Extraer RDF usando un servicio web
La URL de la que vamos a extraer el archivo RDF es el ejemplo que está accesible aquí. Utilizaremos el servicio web que puede usar el método GRDDL para extraer el RDF que está disponible aquí.
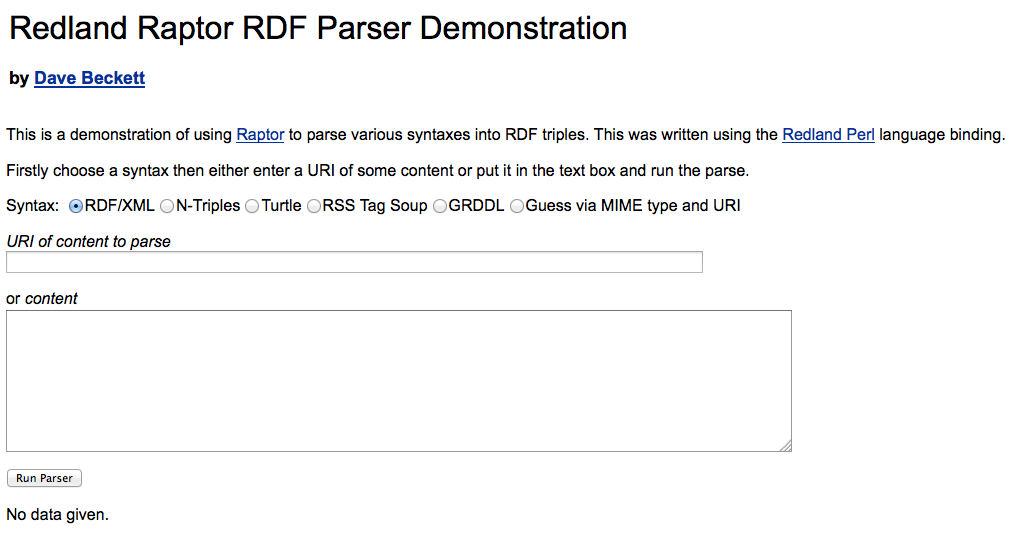
Seleccionamos GRDDL y ponemos la URL que vamos a parsear. También podríamos pegar directamente el código fuente de la página en la ventana más grande.

Por último, pulsamos en "Run Parser" y nos aparecerá una tabla con la información RDF diferenciando entre sujeto, predicado y objeto.

Extraer RDF usando un cliente
Utilizaremos un cliente en bash, aunque podríamos utilizar cualquiera de las implementaciones de GRDDL. En este caso será grddler.sh. Para poder utilizarlo, necesitaremos tener instalados los paquetes python, xsltproc y md5sum.
El uso es muy sencillo, sólo tendremos que ejecutar el script en bash pasándole como argumentos la URL de la que queremos extraer el rdf y el archivo donde queremos almacenar el resultado. Podría ser algo como lo siguiente:
bash ./grddler.sh https://davidr.gitbooks.io/ejemplos-de-linked-data/content/ejemplo_grddl.html > output.rdf
Con esto ya tendremos nuestro RDF extraído y damos por terminado el capítulo.